本文共 2524 字,大约阅读时间需要 8 分钟。
以后博客更新内容都会在中
PASCAL-VOC2012数据集介绍官网: 数据集下载地址:benchmark_RELEASE: voc2012:VOC2012数据集分为20类,包括背景为21类,分别如下:
- Person: person - Animal: bird, cat, cow, dog, horse, sheep - Vehicle: aeroplane, bicycle, boat, bus, car, motorbike, train - Indoor: bottle, chair, dining table, potted plant, sofa, tv/monitor
这里只说与图像分割(segmentation)有关的信息,VOC2012中的图片并不是都用于分割,用于分割比赛的图片实例如下,包含原图以及图像分类分割和图像物体分割两种png图。图像分类分割是在20种物体中,ground-turth图片上每个物体的轮廓填充都有一个特定的颜色,一共20种颜色,比如摩托车用红色表示,人用绿色表示。而图像物体分割则仅仅在一副图中生成不同物体的轮廓颜色即可,颜色自己随便填充。

在FCN这篇论文中,我们用到的数据集即是基本的分割数据集,一共有两套分别是benchmark_RELEASE和VOC2012。
两套都包含了用于分割图片以及label信息。
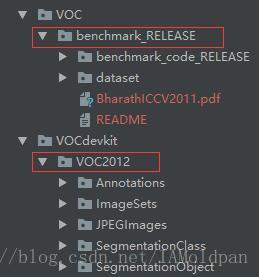
1、首先看benchmark_RELEASE中的数据:
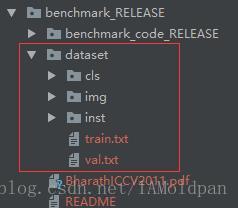
上图中红线标注的信息是我们需要用到的信息,其余的是一些备用信息和说明文档,在dataset中我们可以cls、img、inst分别为 图像分类分割 .mat 格式标注信息 、分割图像以及 图像物体分割 .mat标注信息。
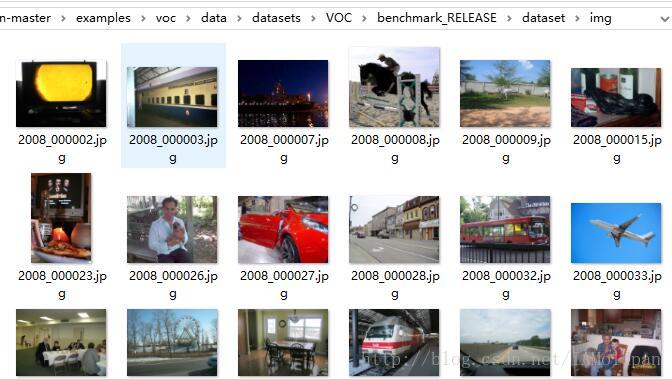
下图为img中的图片:
至于什么是mat格式的信息,看后缀就可以看出是matlab中文件的一种格式,该格式的文件包含了对应分割图片的label位置信息以及图片的其他一些基础信息,下图是cls中挑取一个的信息:
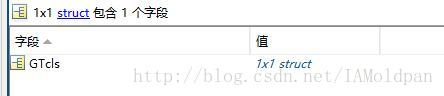
 可以看到CategoriesPresent为12,表示该图片上的物体的分类标号是12,而Segmentation是500 × 375 的 uint8的数据,打开如下:
可以看到CategoriesPresent为12,表示该图片上的物体的分类标号是12,而Segmentation是500 × 375 的 uint8的数据,打开如下: 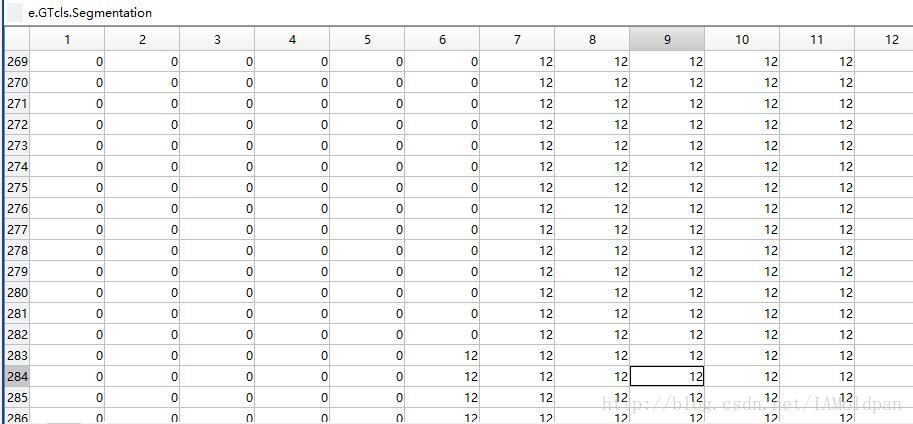
也就是说背景为0,而分割目标物体的像素点事12,注意这相当于一个一通道的灰度图,灰度值0-20分别表示图片中的各种物体标号(背景为0)
然后我们从inst中也挑选与cls对应分割图的信息出来:
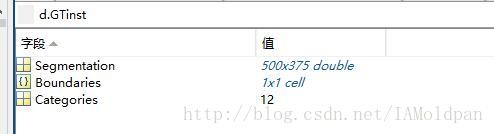
可以看到与之前的cls中的一样,分类表示同样是12,但是打开segmentation看一下就会发现不同:
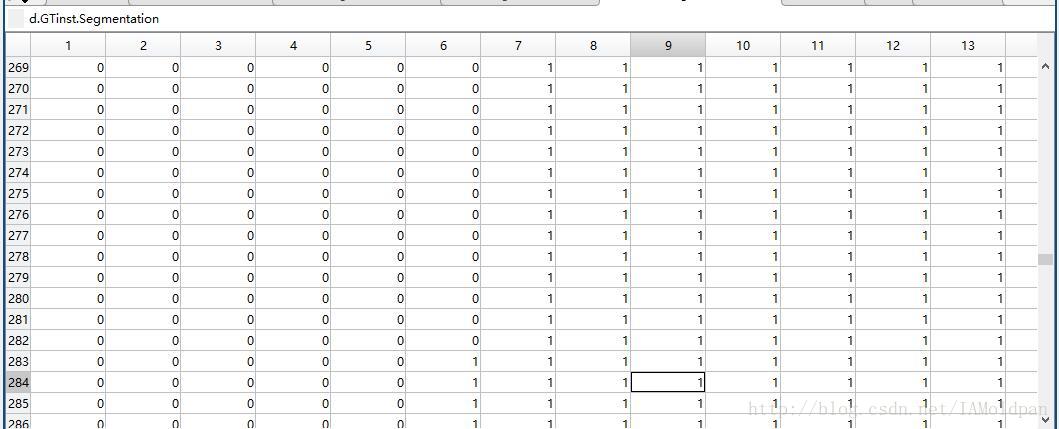
相应的像素点变为了1而不是12,说明在inst中的label信息是为了实现图像物体分割,只要在一幅图中将不同物体分割显示出来即可而不是对不同的物体进行类别标记。
再看从inst中取出的另一个例子:

可以看到有4,4,15,15,15,说明图片中有两类物体(在图像分类分割中,20类中的2类),然后我们打开segmentation看一下:
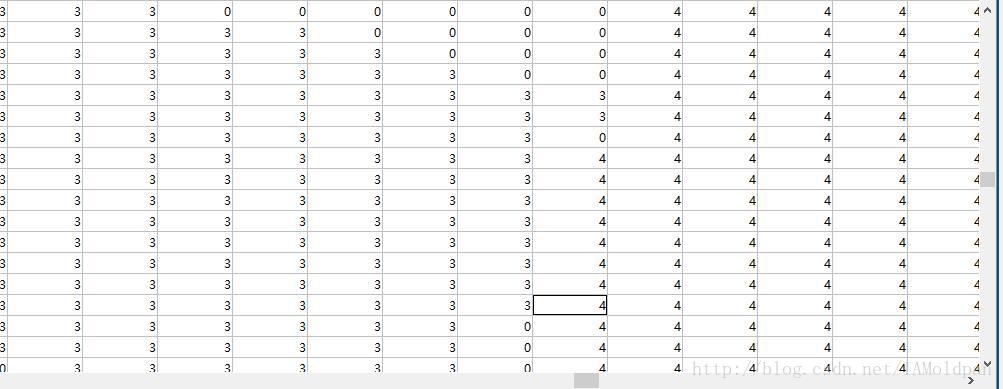
 显然,像素点的范围是0-5,0代表背景,1-5代表图中的五个物体,但这里仅仅是分离出来这几个物体,但并不进行分类标记,如果从cls中打开的label,那么上面的1-5应该对应为4,4,15,15,15,要求标出具体的类别。
显然,像素点的范围是0-5,0代表背景,1-5代表图中的五个物体,但这里仅仅是分离出来这几个物体,但并不进行分类标记,如果从cls中打开的label,那么上面的1-5应该对应为4,4,15,15,15,要求标出具体的类别。 2、其次看一下VOC2012中的数据
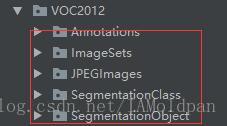
VOC2012中的数据比较规整一些,其中Annotation中包含了对应图片的xml信息:
我们以下面的2007_000032.jpg为例
其Annotation中对应的xml信息为:
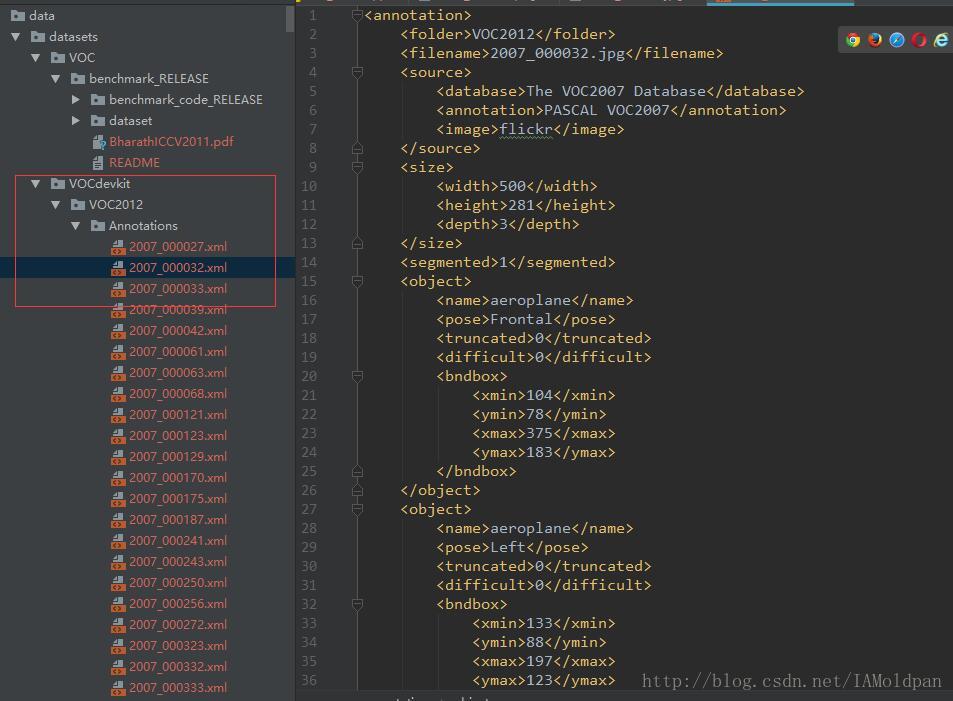
xml信息包含了该图片的基本信息,xml语言很易读,我们从中可以轻易得出这幅图片的一些基本信息,其中segmented一栏为1,这里的意思是这幅图用于分割(因为VOC2012中一共有10000+图,但并不都用于分割任务,有的用以物体标识或者动作识别等),若这一栏为0说明这幅图不是用于图像分割的。
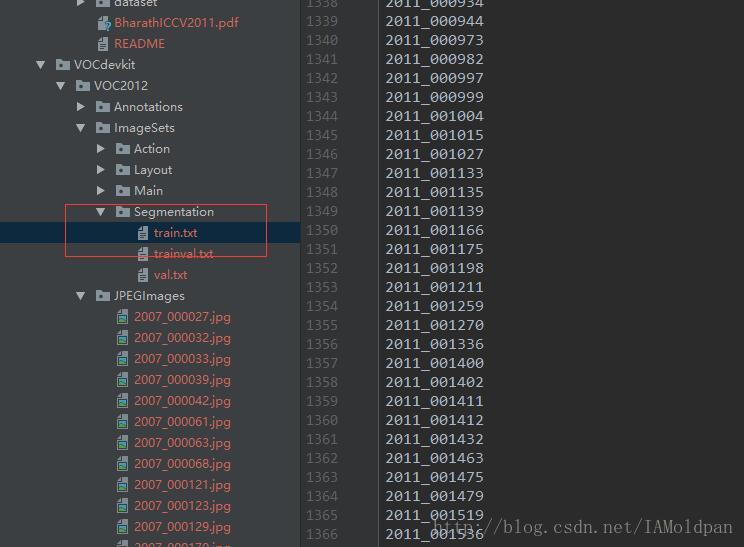
因为VOC2012中的图片并不是都用于分割,所以需要txt文件信息来标记处哪些图片可以用于分割,写程序的时候就可以利用信息 train.txt 对图片进行挑选。train和val中的图片加一起一共2913张图。
SegmentationClass中的png图用于图像分割分类,下图中有两类物体,人和飞机,其中飞机和人都对应着特定的颜色,注意该文件夹中的图片为三通道彩色图,与之前单通道的灰度图不同。png图中对物体的分类像素不是0-20,而是对应着不同的RGB分量:

而SegmentationClass中precoded中的图片为:
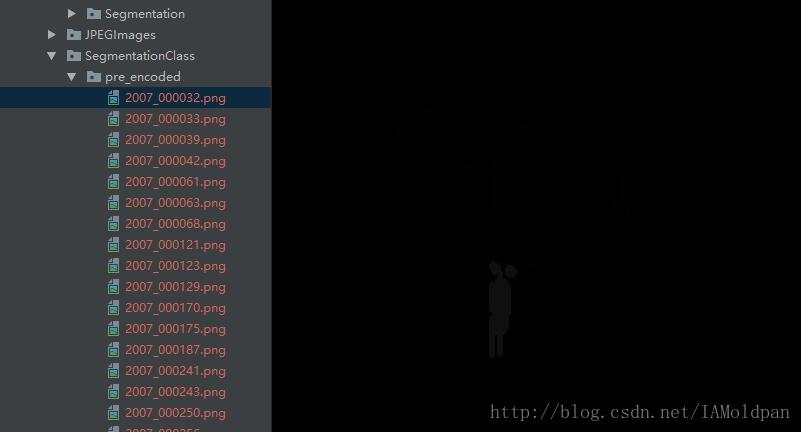
为什么说是precoded,我们可以看到这幅图也是png格式的,我们可以大概看到分类物体的轮廓填充信息,但是没有之前的清晰,我们分析一下其中的像素值:
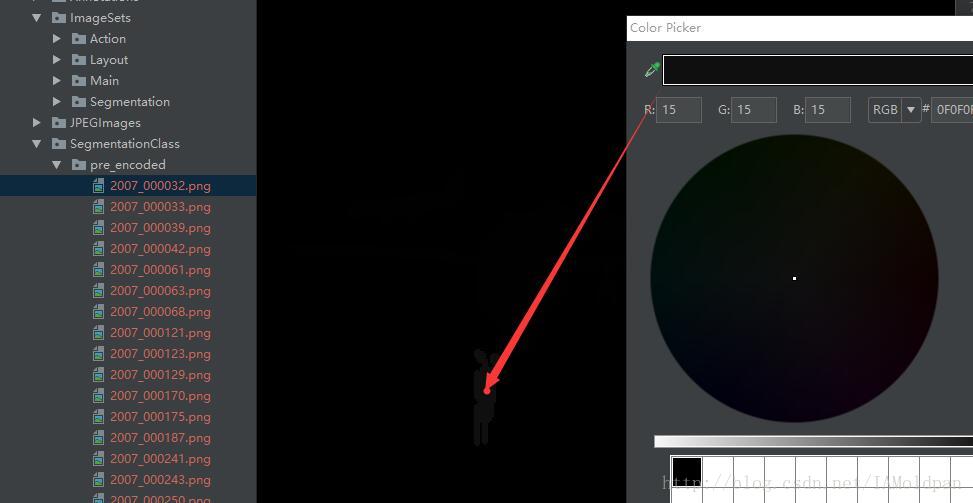
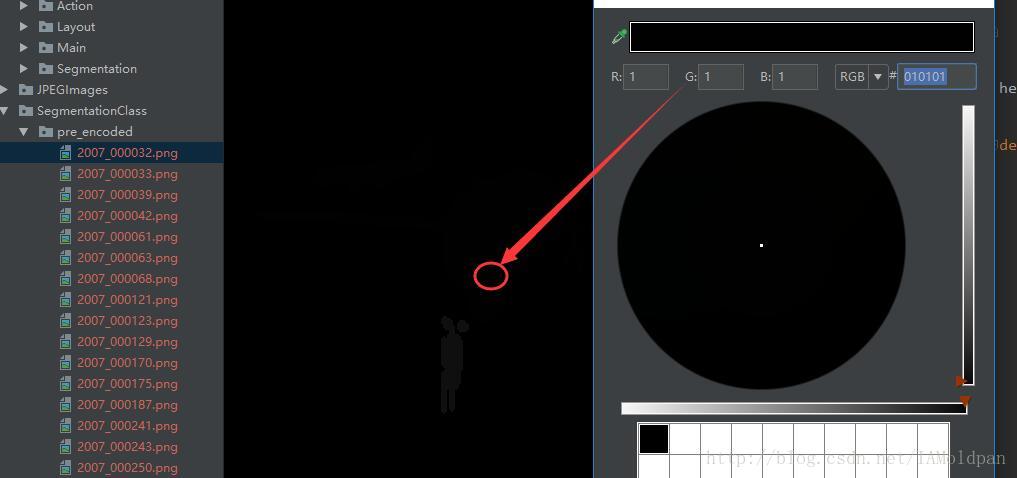
可以发现这里的RGB都是同一个值,其中人代表的RGB值为(15,15,15),而飞机代表的为(1,1,1),也就是说,precoded中的图片相比于之前的png图将不同类别代表的颜色(假如飞机为(0,255,255))“变为”了1而人代表15,和benchmark中的数据集分类的表示方式就类似了。
而SegmentationObject中的png图则仅仅对图中不同的物体进行的分割,不对其物体所属的类别进行标注:
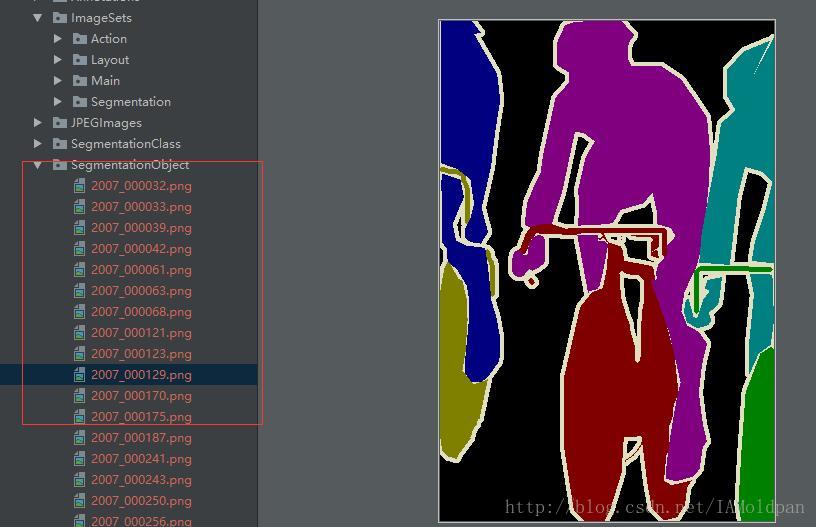
显然,上面的很多人都被标记了不同的颜色,当然仅仅是为了分离出来。
JPEGimages则放了我们需要的图片,这些图片一共有17125张,我们并不是都使用,我们仅对train.txt和val.txt中列出的图像进行使用,而其他的图像则用于不同的任务中。
总结
图像分割的数据集一般都是采用上面说明的VOC2012挑战数据集,有人说benchmark_LELEASE为增强数据集,具体原因我不清楚,可能是因为benchmark_LELEASE的图片都是用于分割(一共11355张),而VOC2012仅仅部分图片适用于分割(2913张)吧。
我们自己制作数据集的时候,只需要图像的json、xml分割信息就可以通过程序生成对应的png轮廓图,下一节中说明如何制作自己的适用于FCN、deeplab算法的图像分割数据集。